


MOTIVATION AND OBJECTIVE
Current 4G LTE scheduling is based on maintaining a balance between two competing interests: trying to maximize total throughput of the network (wired or not) and allowing all users at least a minimal level of service. This leads to inefficient resource block allocation in the LTE architecture. Thus, there is a need for an intelligent system that allows scheduling based on different data packets received. The software implementation of the 4G LTE architecture on Orbit testbed and subsequent learning algorithms provides for such an intelligent system.


Fig: Experimental Setup for Data Generation
DATA COLLECTION
We begin our study with software implementation of the 4G LTE architecture on Orbit Testbed. We run multiple user applications such as YouTube, Skype, Mail transfer, and world wide web navigation. This provides us with the user dataset further utilized in our machine learning algorithms for classification.


CLUSTERING

Fig: Inertia / Distortions vs Number of Clusters (Elbow Method) and generating labels and cluster centroids
CLUSTERING
-
Clustering is a method of grouping together similar instances or data points so that data points that are similar to each other are closer together in a cluster and data points that are different from each other are far away.
-
Clustering is a form of unsupervised learning where there is a lack of an associated response variable.
-
In this project, the goal is to group together computer network traffic data based on similar features (like MCS, number of resource blocks, packet size) in distinct clusters
-
Method of clustering used: KMeans Clustering
-
KMeans Clustering is a machine learning algorithm that clusters data points based on distance.
-
Elbow Method is used to find the number of clusters.
-
It also generates and assigns labels to the data points.
-
-
Elbow Method is a method of finding the optimal number of clusters by plotting a graph of the average within-cluster sum of the squares errors and the number of clusters. The number of clusters corresponding to which the within-cluster error is the minimum is the optimal number of clusters.
K MEANS CLUSTERING


Fig: A KNN Classifier helps us classify data with respect to its neighbors
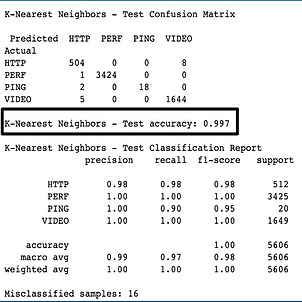
Fig: Output snippet with Python code highlighting testing accuracy
CLASSIFICATION
-
Classification is a form of supervised learning where the computer learns the patterns and the classes from the data inputs and uses it to classify new observations.
METHOD 1: KNN CLASSIFIER
-
KNN Classifier is used to predict the class of a data point based on the class of its neighbors.
-
It classifies the application data as Video, PING, PERF or HTTP.
-
A confusion matrix showing the number of correctly classified samples and the number of incorrectly classified samples is also shown in the figure.
-
The test accuracy is 99.7%. The accuracy is high due to the absence of "False Positive" and "False Negative" data values.
CONCLUSION AND FUTURE WORK
The implementation of 4G LTE architecture allows us to
emulate single user, single user hybrid, and multiple users
traffic data environment.
The Clustering algorithm provides us with two clusters for
each application, with one referencing the application data
packets and the other referencing control signals. The
machine learning algorithms help us to classify data with
extremely high accuracy. The high accuracy is observed
because of a few (~10) features describing a particular class.
Increasing the feature list lead to complications in labeling.
Our future work would address identifying more features as
well as improve the labeling for our dataset. Since we performed classification on a dataset with only four features obtained form a single user, we hope to combine all the features in an integrated dataset and run our machine learning algorithms on it for single-user hybrid and multiple users.